Uit welke woorden bestaat DigiD? Hoe is het woord glamping opgebouwd? In Taalradar, een nieuw crowdsourcingexperiment, verzamelt het Instituut voor de Nederlandse Taal kennis over samenstellingen. Helpt u mee?
Na de succesvolle COST-actie (COST is een organisatie die wetenschappelijke samenwerking in Europa stimuleert) European Network of e-Lexicography (ENeL) is het Instituut voor de Nederlandse Taal opnieuw betrokken bij een dergelijke actie: enetCollect (european network for Combining language learning with crowdsourcing techniques). Binnen dit project wordt gekeken naar de mogelijkheden om crowdsourcing in te zetten bij het maken van materiaal voor het leren van een taal. Crowdsourcing is het gebruikmaken van de kennis van de menigte. In ons geval zijn dat sprekers van het Nederlands.
Experiment
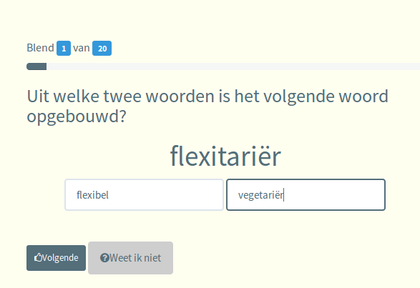
Voor crowdsourcing maken we gebruik van PYBOSSA, een opensourceplatform waarop taken kunnen worden geplaatst die door mensen van buitenaf kunnen worden uitgevoerd. Om ervaring op te doen met dit platform, hebben we een kort experiment opgezet dat bestaat uit het herkennen en analyseren van blends, samenstellingen die bestaan uit stukjes van twee andere woorden. Zo is het woord infotainment een samensmelting van informatie/information en entertainment.

Doe mee!
Helpt u mee om onze kennis te vergroten? Ga naar taalradar.ivdnt.org en doe mee met ons experiment.
Laatste nieuwsberichten:
- ‘Brus’ in het woordenboek
- Podcast: Superbrabants
- Digitaaljaar: Carole en computerlinguïstiek
- Over taal gesproken genomineerd voor Language Industry Award
- Persbericht: Samenwerkingsverband Nationaal Taalinstituut Curaçao en Instituut voor de Nederlandse Taal
Of bekijk alle nieuwsberichten.